MIRA is an agile and modular software platform that integrates with key clinical systems to facilitate the development, deployment, and automation of data-driven pipelines in the clinical environment.
Transforming Clinical Data into Actionable Insights
Medicine is rapidly evolving into a data-driven field. More than ever, scientists and clinicians at the Princess Margaret are leveraging digital intelligence to drive innovations in precision medicine, predictive analytics, real-time monitoring and decision support. However, large-scale operationalization of data science in the clinical environment is hindered by the lack of flexible and reliable software tools to:
- Extract clinical data from disparate and evolving sources
- Process the data in an efficient and reproducible manner
- Integrate validated data-driven pipelines back into clinical workflows
The MIRA platform provides a scalable enterprise solution to these data science workflows and enables clinicians and researchers at the Princess Margaret to develop custom data-driven pipelines for both retrospective analysis and prospective clinical integration.
Code Meets Context
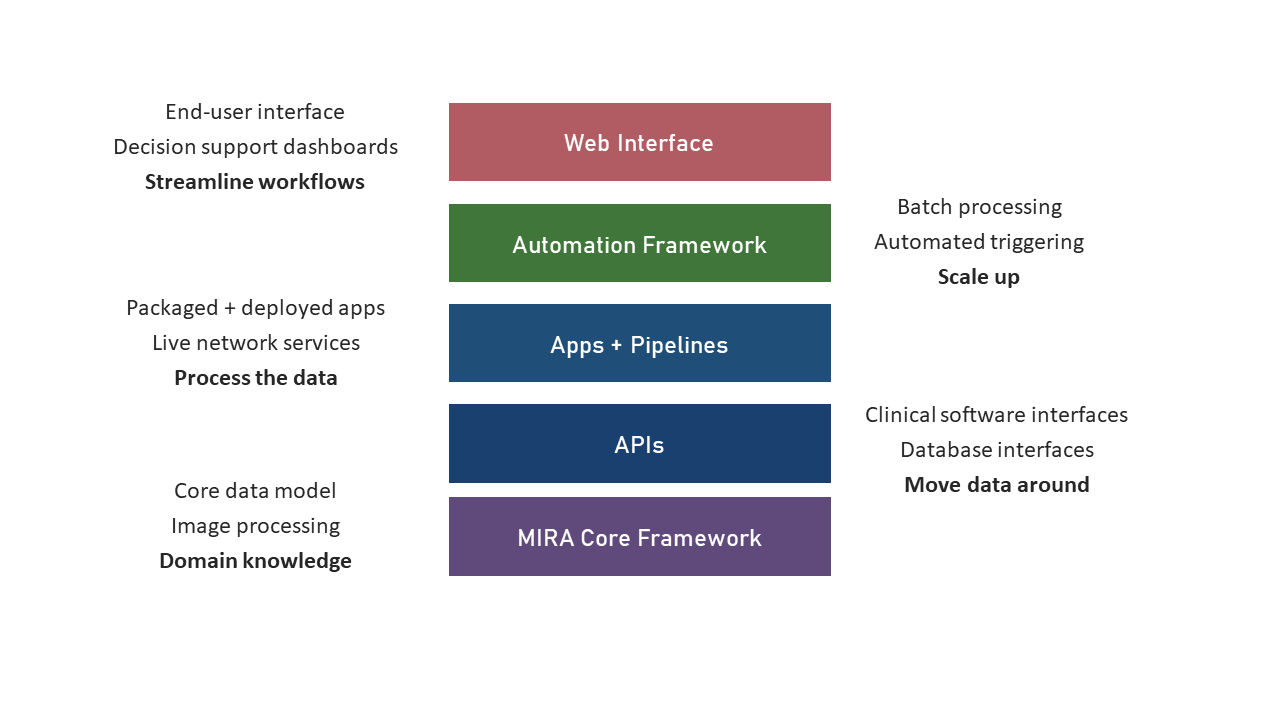
MIRA is composed of several layers built upon one another to provide increasingly powerful and streamlined functionality.
MIRA Core Framework: The foundational code underpinning the entire platform. The core framework consists of our core data model and fundamental image processing modules. This layer transforms our domain knowledge into building blocks for creating data-driven software.
Application Programming Interfaces (APIs): A growing stack of interfaces built from the core framework that provide interactive connectivity to an array of clinical and research systems across the hospital.
Apps + Pipelines: The core framework and APIs provide a platform for developers to build data processing pipelines or packaged apps that bury the complexity of the code and can be used to process the data.
Automation Framework: The team has built a flexible automation framework that allows us to conduct batch processing with any of our pipelines, automatically detect and process new data, and enable automated documentation and communication.
Web App: This is the most tangible layer. This provides a portal into MIRA to enable end users to leverage the functionality of the platform for their projects or clinical applications.
Data Sources
In MIRA, we pull data from a variety of data sources and servers across the hospital. Our data sources also extend to clinical and internal databases.
| Radiation Treatment Planning & Review Systems | Hospital Information Systems | Imaging Repositories |
| Pinnacle Raystation EVOQ Web Publishing |
Epic Mosaiq Aria |
JDMI PACS RMP PACS (MDD) PMH Dental PACS RMP XVI CBCT Archive |
Use Cases of MIRA:
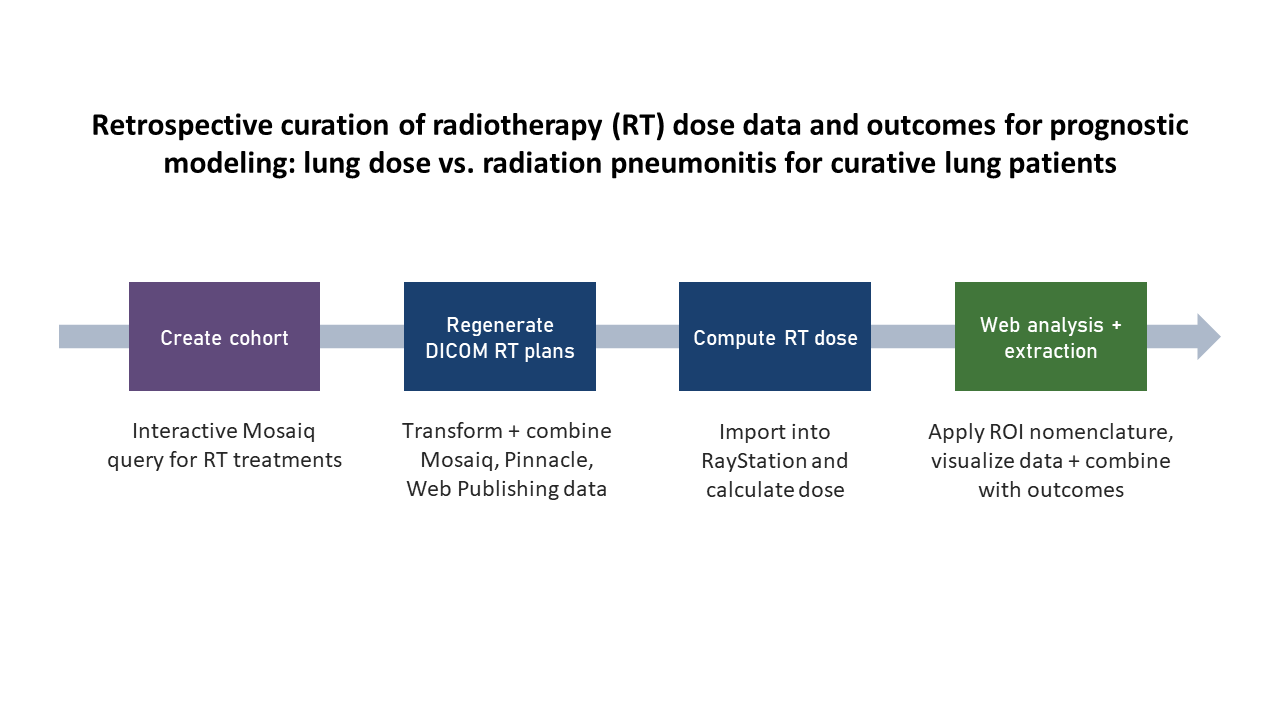
Use Case 1: Archetypal RT Data Mining + Outcomes
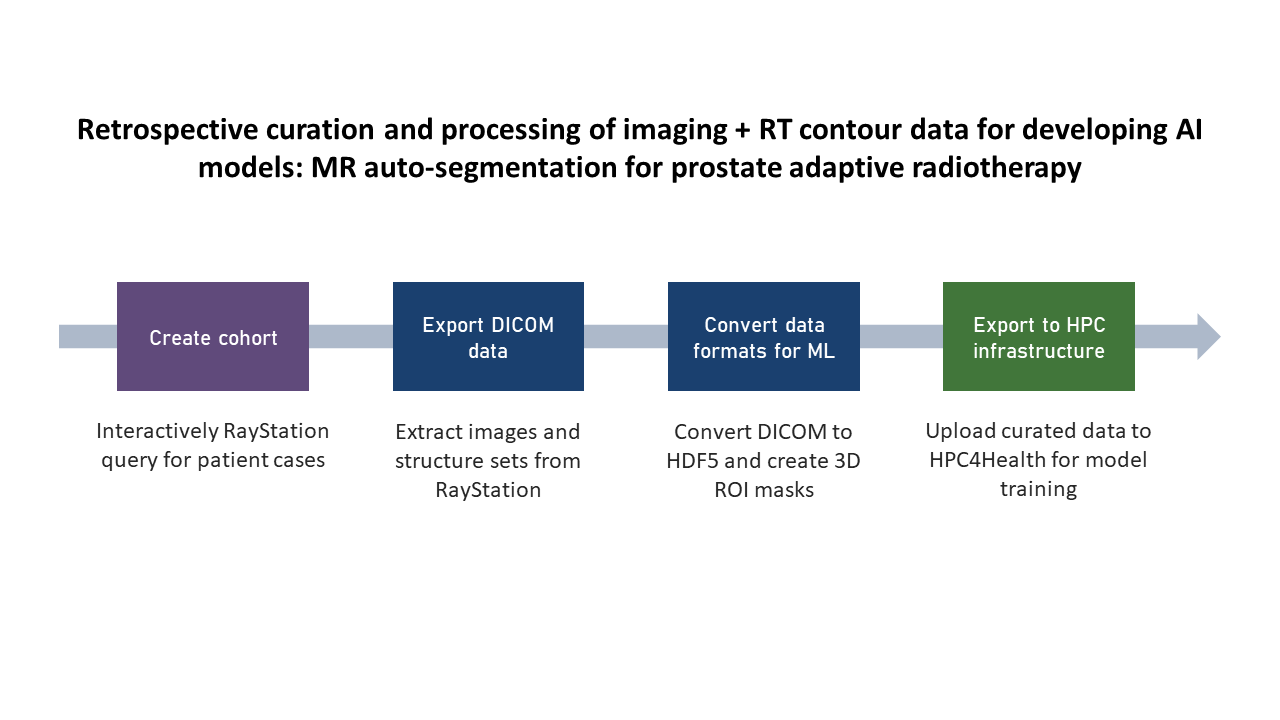
Use Case 2: Image Mining and Processing for AI
Use Case 3: Clinical AI Model Deployment
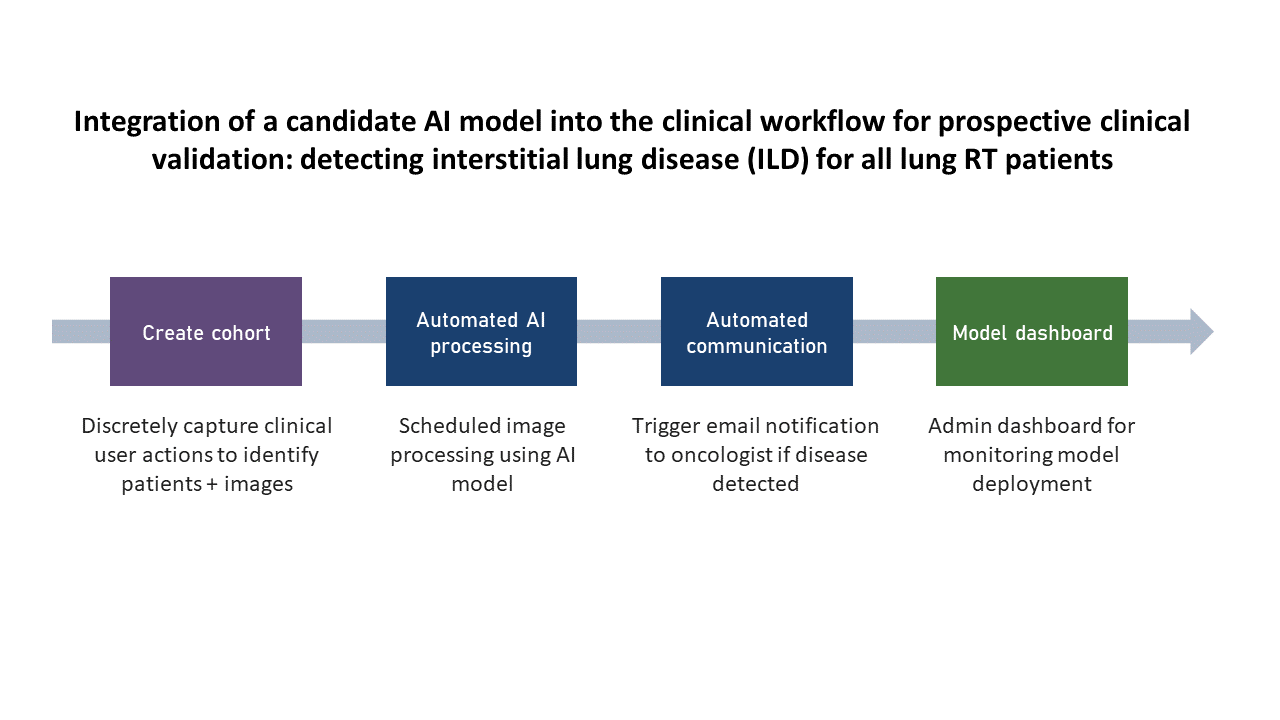
One of the key applications of MIRA is the development of the MIRA Clinical Learning Environment (MIRA-CLE) for lung disease. Machine learning models have been developed and tested along three aims to highlight lung cancer patients who might be prone to other risks and treatment toxicities. Learn more: MIRACLE – CDI (pmcdi.ca)
Upcoming Work
- Completing web UI development, styling and user management for the internal release of the MIRA web app
- Continue developing privacy controls for research vs clinical use
- Streamline data integration between clinical systems to reduce manual curation
- Deploy new clinical apps and pipelines
Contact
The MIRA team is composed of: Tony Tadic, Tirth Patel, Gregory Bootsma, Christopher Da Silva, and Helena Hyams. For more information on MIRA, or for a demo of the web app, please reach out to either: tony.tadic@uhn.ca, or pmcdi@uhn.ca

Tony Tadic

Helena Hyams

Tirth Patel

Gregory Bootsma
