AFFRM-AI
A Framework for Fair and Responsible Machine-learning and AI
Learn how to responsibly, safely, and compassionately develop and deploy AI solutions for healthcare.
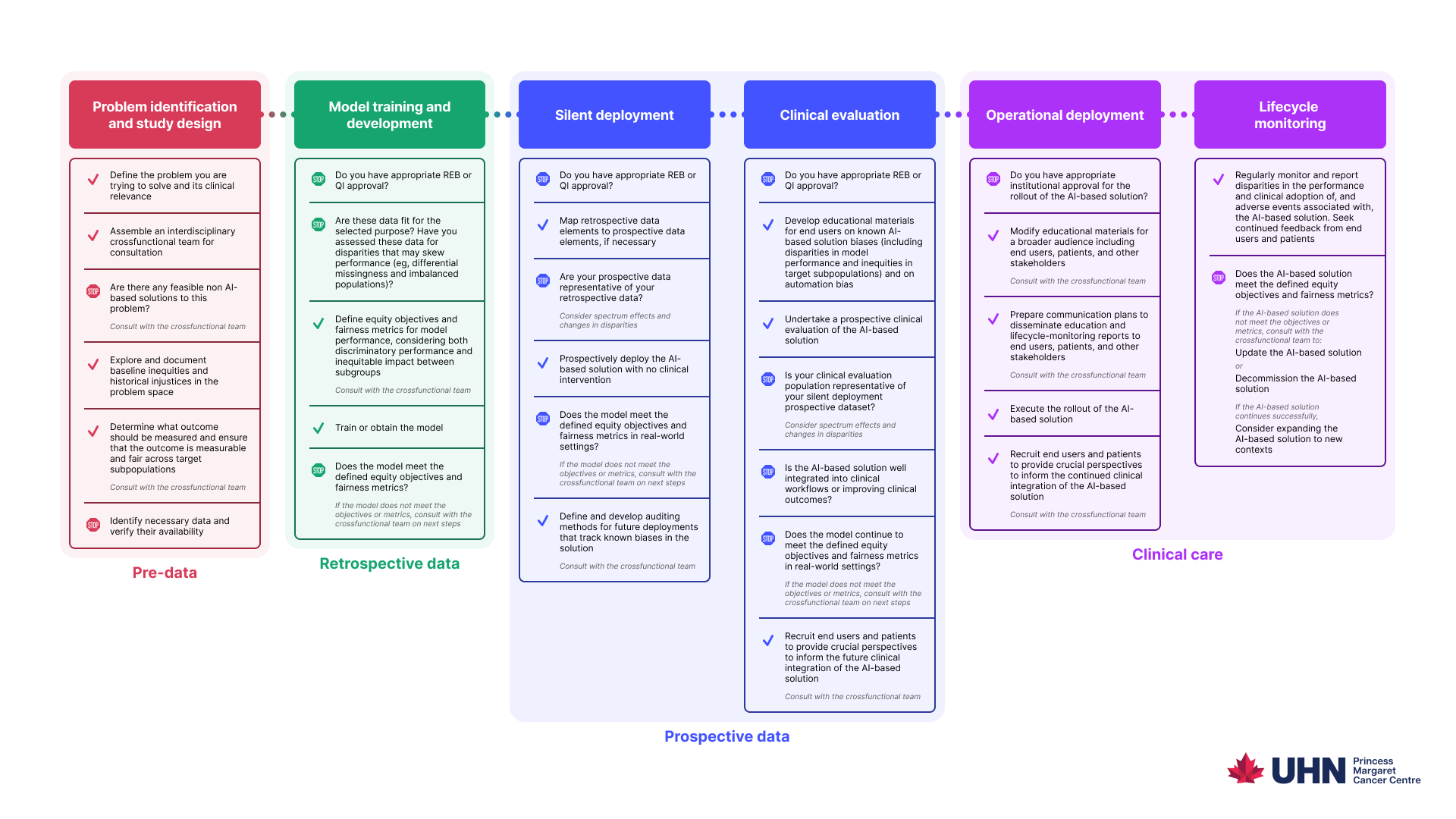
Learn how to responsibly, safely, and compassionately develop and deploy AI solutions for healthcare.